
Hadoop is an effective tool for handling large data. It splits big datasets into smaller chunks for processing across multiple computer systems. Hadoop is utilized in various fields for tasks such as data analysis, machine learning, and more.
Through this manual, you will learn the procedure to set up Hadoop on Linux-based systems (i.e.Ubuntu 22.04).
How to Install Java Development Kit (JDK) for Hadoop on Ubuntu 22.04?
First thing first, using the given below step install Java for Hadoop on your Ubuntu 22.04 operating system.
Step 1: Update Ubuntu Repository
Initiate the installation process by updating your Ubuntu package list:
sudo apt update |
|---|
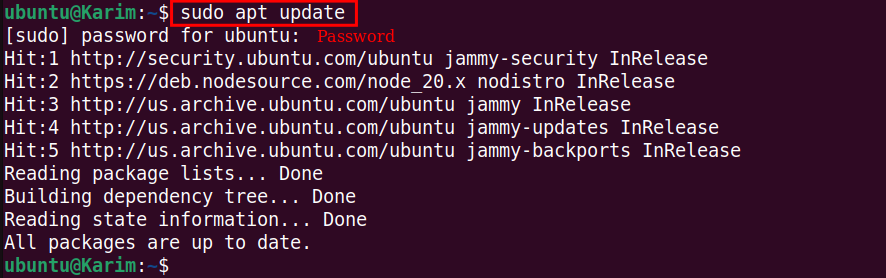
Make sure you have the above message after executing the command.
Step 2: Install Java Package
Hadoop is dependent on Java, so the first step is to install the default version of the Java Development Kit (JDK) on your system:
sudo apt install default-jdk |
|---|
Step 3: Verify Java installation
The Java installation can be confirmed using the command:
java -version |
|---|

How to Install Hadoop on Ubuntu 22.04?
In this section, operate these commands to install Hadoop on your Linux system like Ubuntu 22.04.
Step 1: Access the Hadoop Binary File
Navigate to the official Apache Hadoop website to access the latest stable release of the Hadoop binary file, which will be downloaded and installed on your system:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz |
|---|
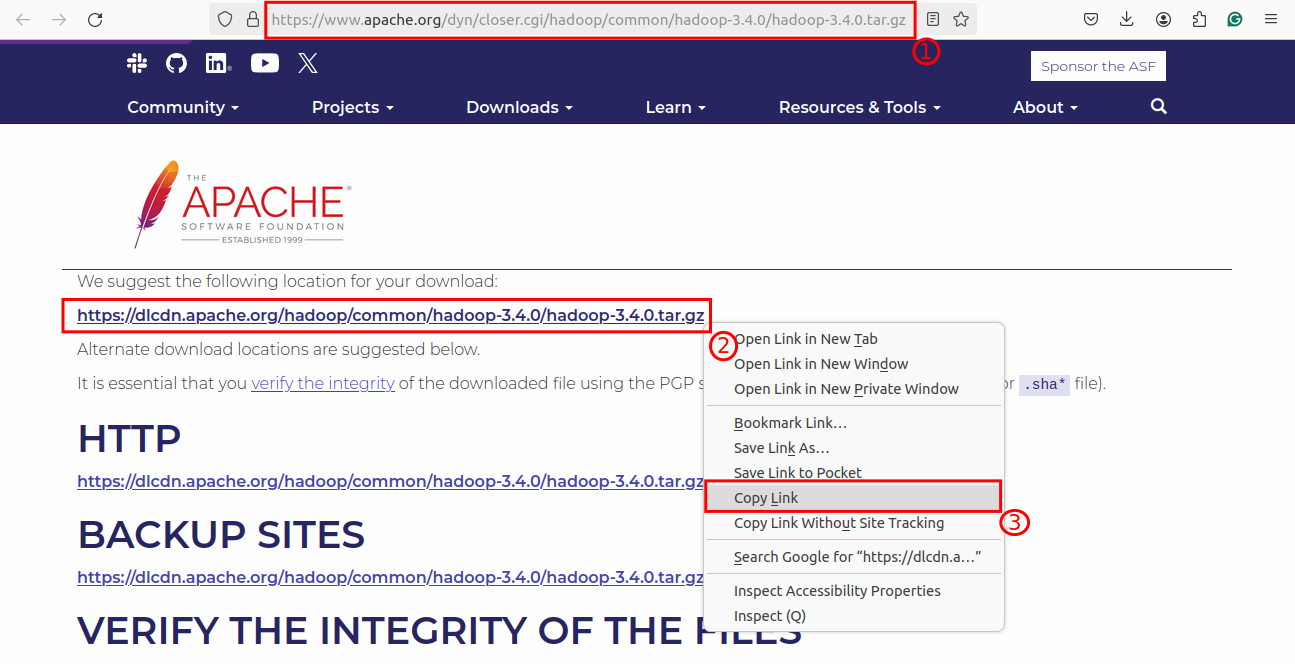
Step 2: Download Hadoop Binary File (.tar)
After copying the link, use the wget command to download the Hadoop binary file in tar extension:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz |
|---|
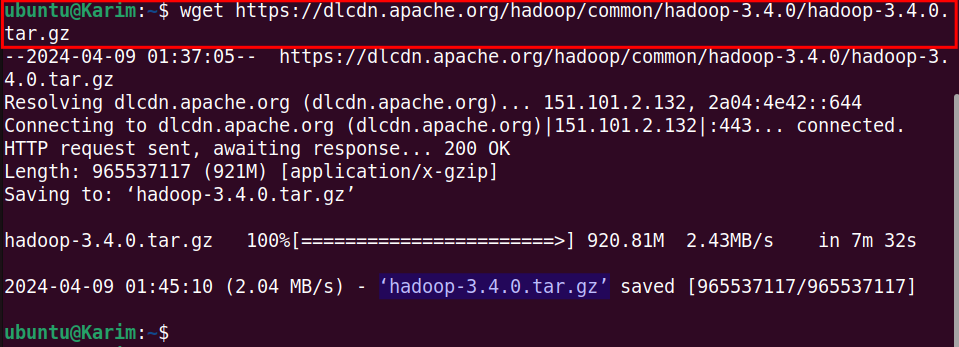
The binary file named hadoop-3.4..0.tar.gz has been saved to your current path.
Step 3: Extract Hadoop Binary File (.tar)
To utilize the Hadoop file, first, you need to extract the tar file through the command:
tar -xzf hadoop-3.4.0.tar.gz |
|---|

Step 4: List Hadoop After Extraction
After the successful extraction of the Hadoop tar file, let’s verify the file using the command:
ls |
|---|

You will see the “hadoop-3.4.0” folder after extraction.
Step 5: Move the Hadoop to “/usr/local”
Now, let’s move the extracted Hadoop file to the local path:
sudo mv hadoop-3.4.0 /usr/local/hadoop |
|---|
Step 6: Locate Java Path
The command will show the absolute path to the Java executable files:
readlink -f /usr/bin/java | sed "s:bin/java::" |
|---|

This path is necessary for configuring the Hadoop package.
Step 7: Modify the Hadoop Configuration File
Open the “hadoop-env.sh” file, which is located at the “/usr/local/hadoop/etc/hadoop/” using Nano editor:
sudo nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh |
|---|
Locate “export JAVA_HOME=” in the Hadoop configuration file, usually placed in line number 52. Add these lines and uncomment the relevant line of code according to your need:
# For static Location: #export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/ # For dynamic location: export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") |
|---|
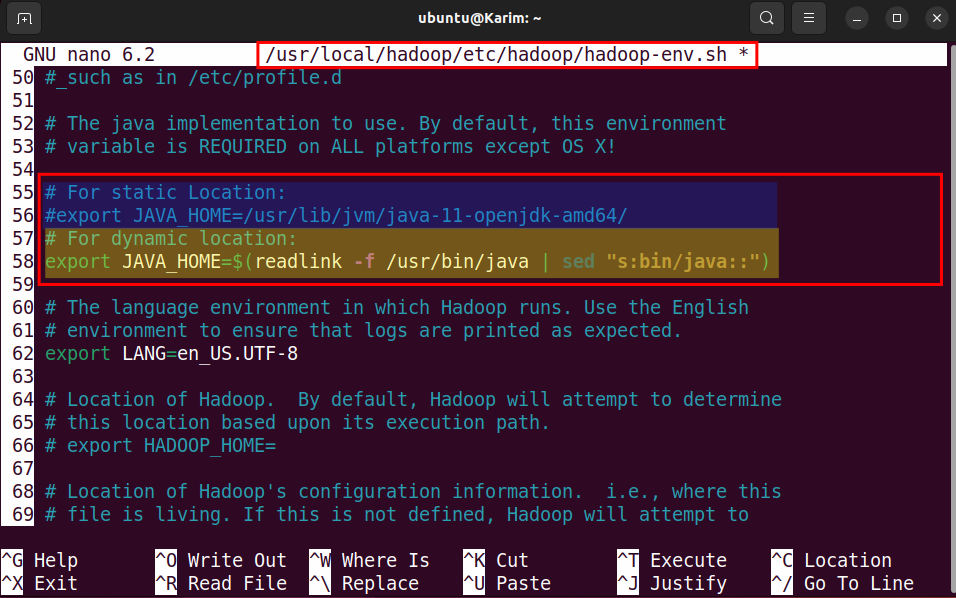
Note: To display line numbers in the Nano text editor, you can press the combination “Alt + N”
Step 8: Verify Hadoop Installation
To check if the Hadoop is installed correctly by using the command:
/usr/local/hadoop/bin/hadoop version |
|---|
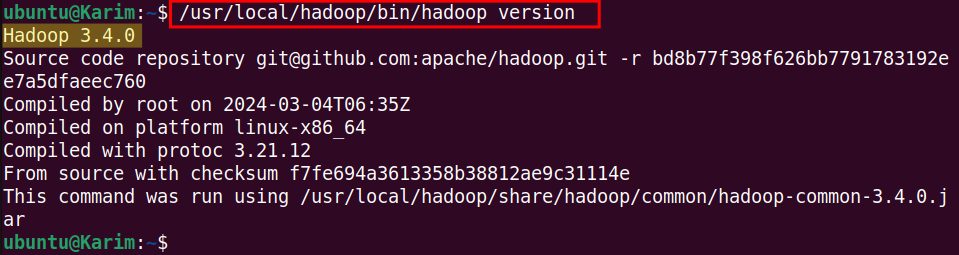
You will see the Hadoop version details (i.e. Hadoop 3.4.0) in the output if Hadoop is installed on your Ubuntu 22.04 system.
Conclusion
Hadoop can be installed on Linux-based systems, including Ubuntu 22.04. Hadoop is dependent on Java, so install the default JDK first. Then, download and extract the Hadoop binary file. Finally, update the Hadoop configuration file with “export JAVA_HOME=$(readlink -f /usr/bin/java | sed “s:bin/java::”)”.






Leave feedback about this